SPARTA
SPARTA is a collection of open-source audio plug-ins for the production and playback of spatial sound scenes.
All Ambisonics-related plug-ins conform to the Ambisonic Channel Number (ACN) ordering convention and offer support for both orthonormalised (N3D) and semi-normalised (SN3D) normalisation schemes (note that the AmbiX format refers to the combination of ACN and SN3D). The maximum transform order for these plug-ins is 10th.
Thanks to the efforts of Daniel Rudrich, the relevant plug-ins also support importing and exporting loudspeaker, source, and sensors directions via .json configuration files; thus allowing for cross-compatibility between SPARTA and the IEM Ambisonics plug-in suite. More information regarding the structure of these files can be found here.
Plug-in descriptions
Example REAPER projects can be found here.
AmbiBIN
Input: Ambisonics | Output: Binaural
A binaural Ambisonic decoder with head-tracking support via OSC messages. The plug-in also supports importing custom HRIRs via the SOFA standard. The default HRIR set is an 836-point simulation of a Kemar Dummy head, courtesy of Genelec AuralID. The plug-in offers a variety of different decoding methods, including: Least-Squares (LS), Spatial re-sampling (SPR, virtual loudspeakers), Time-Alignment (TA) [10], and Magnitude Least-Squares (MagLS) [11]. It can also impose a diffuse-coherence constraint for the current decoder, as described in [10].
Developers: Leo McCormack, Archontis Politis, and Christoph Hold.
AmbiDEC
Input: Ambisonics | Output: Arbitrary loudspeaker array
A frequency-dependent Ambisonic decoder. The loudspeaker directions can be user-specified for up to 128 channels, or alternatively presets for popular 2D and 3D set-ups can be selected. Optionally the loudspeaker audio can be convolved with interpolated HRTFs for each loudspeaker direction (i.e. virtual loudspeaker decoding). The plug-in also permits importing custom HRIRs via the SOFA standard.
The plug-in employs a dual decoding approach, whereby different decoder settings may be selected for the low and high frequencies. Several ambisonic decoders have been integrated, including the All-Round Ambisonic Decoder (AllRAD) [1] and Energy-Preserving Ambisonic Decoder (EPAD) [2]. The popular max-rE weighting/spatial-tapering [1] may also be enabled for either decoder. Different decoding orders may also be specified for different frequency ranges.
Note that when the loudspeakers are uniformly distributed (e.g. a t-design), all of the included decoding approaches, except for AllRAD, become equivalent. The benefits of the Mode-Matching decoding (MMD), AllRAD and EPAD approaches may be observed for non-uniform arrangements (22.x for example).
Developers: Leo McCormack and Archontis Politis.
AmbiDRC
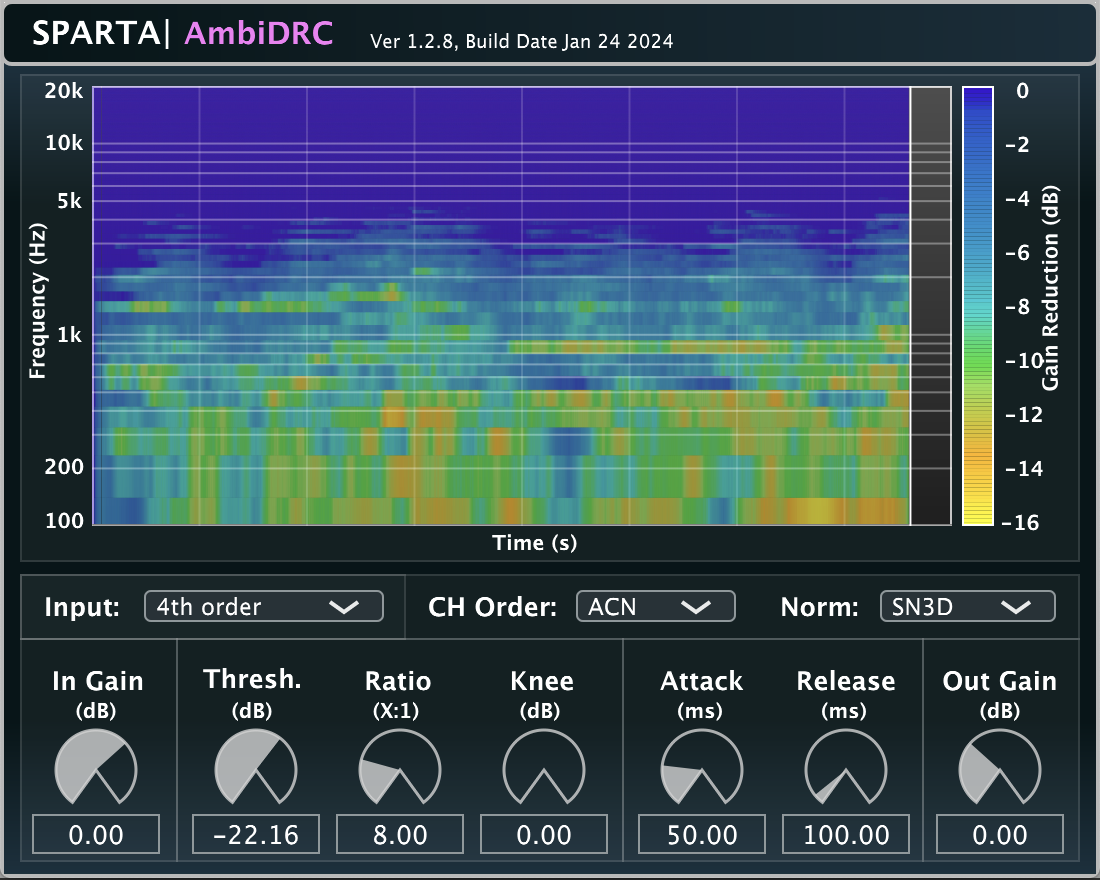
Input: Ambisonics | Output: Ambisonics | Related publication
A frequency-dependent Ambisonic dynamic range compressor (DRC). The gain factors are derived by analysing the omnidirectional component for each frequency band, which are then applied equally to all Ambisonic channels. Therefore, the spatial properties of the scene will remain unchanged; although, your perception of the compressed scene (after decoding) may change.
Developers: Leo McCormack
AmbiENC
Input: Object audio signals | Output: Ambisonics
An Ambisonic encoder that takes input signals (up to 128 channels) and encodes each channel/signal into Ambisonic signals at specified directions. These Ambisonic signals describe a synthetic sound scene, where the spatial resolution of the sound scene is determined by the encoding order. Several presets have been included for convenience, which allow for 22.x etc. audio to be encoded into 1-10th order Ambisonics, for example.
Developers: Leo McCormack
AmbiRoomSim
Input: Object audio signals | Output: (multi-)Ambisonics
An Ambisonic encoder that also models wall reflections for a shoebox room using the image source method. Multiple sources and multiple Ambisonic receivers are supported up to a combined 128 channels; e.g. 32x first-order or 8x third-order receivers, 2x 7th-order receivers, or 1x 10th order receiver. The output receiver channels are stacked, e.g. 1-4 channels are for the 1st first-order receiver, 5-8 for the second etc.
Developers: Leo McCormack
Array2SH
Input: Microphone array signals | Output: Ambisonics | Related publication
‘Array2SH’ encodes spherical/cylindrical array signals into spherical harmonic (SH; AKA Ambisonic) signals. The plug-in allows the user to specify: the array type (spherical or cylindrical), whether the array has an open or rigid enclosure, the radius of the array, the radius of the sensors (in cases where they protrude out from the array), the microphone/hydrophone coordinates (up to 128 channels), sensor directivity (omni-dipole-cardioid), and the speed of sound (so that both microphone and hydrophone arrays are supported). The plug-in then determines the order-dependent equalisation curves that need to be imposed onto the initial Ambisonic signals estimate, in order to remove the radial influence of the array itself. However, especially for higher-orders, this generally results in a large amplification of the low frequencies (including the sensor noise at these frequencies that accompanies it); therefore, four different regularisation approaches have been integrated into the plug-in, which allow the user to make a compromise between noise amplification and transform accuracy.
The plug-in also allows the user to ‘Analyse’ the spatial encoding performance using objective measures described in [7,8], namely: the spatial correlation and the level difference. Here, the encoding matrices are applied to a simulated array. The spatial correlation metric is derived by comparing the produced Ambisonic patterns with ideal Ambisonic patterns, where ‘1’ means they are perfect, and ‘0’ means they are uncorrelated; the spatial aliasing frequency can therefore be observed for each order, as the point where the spatial correlation tends towards 0. The level difference is then the mean level difference over all directions (diffuse level difference) between the ideal and simulated components. A higher permitted amplification limits [Max Gain (dB)] will result in noisier signals; however, this will also result in a wider frequency range of useful Ambisonic components at each order. This analysis is primarily based on code written for publication [8].
For convenience, the specifications for several commercially available microphone arrays have been integrated as presets; including: mh Acoustic’s Eigenmike32/Eigenmike64, the Zylia array, and various open-tetrahedral microphone arrays.
Developers: Leo McCormack, Symeon Delikaris-Manias and Archontis Politis.
Beamformer
Input: Ambisonics | Output: Object audio signals
A simple beamforming plug-in, which can produce the following static beamformer patterns for arbitrary directions: cardioid, hyper-cardioid, or max_rE weighted hyper-cardioid.
Developers: Leo McCormack
Binauraliser
Input: Object audio signals | Output: Binaural
A plug-in that convolves input audio (up to 128 channels) with interpolated HRTFs. The plug-in also allows the user to specify an external SOFA file for the convolution. The directions for up to 128 channels can be independently controlled. Presets for popular 2D and 3D formats are included for convenience. Head-tracking is also supported via OSC messages in the same manner as with the Rotator plug-in.
Developers: Leo McCormack and Archontis Politis.
BinauraliserNF
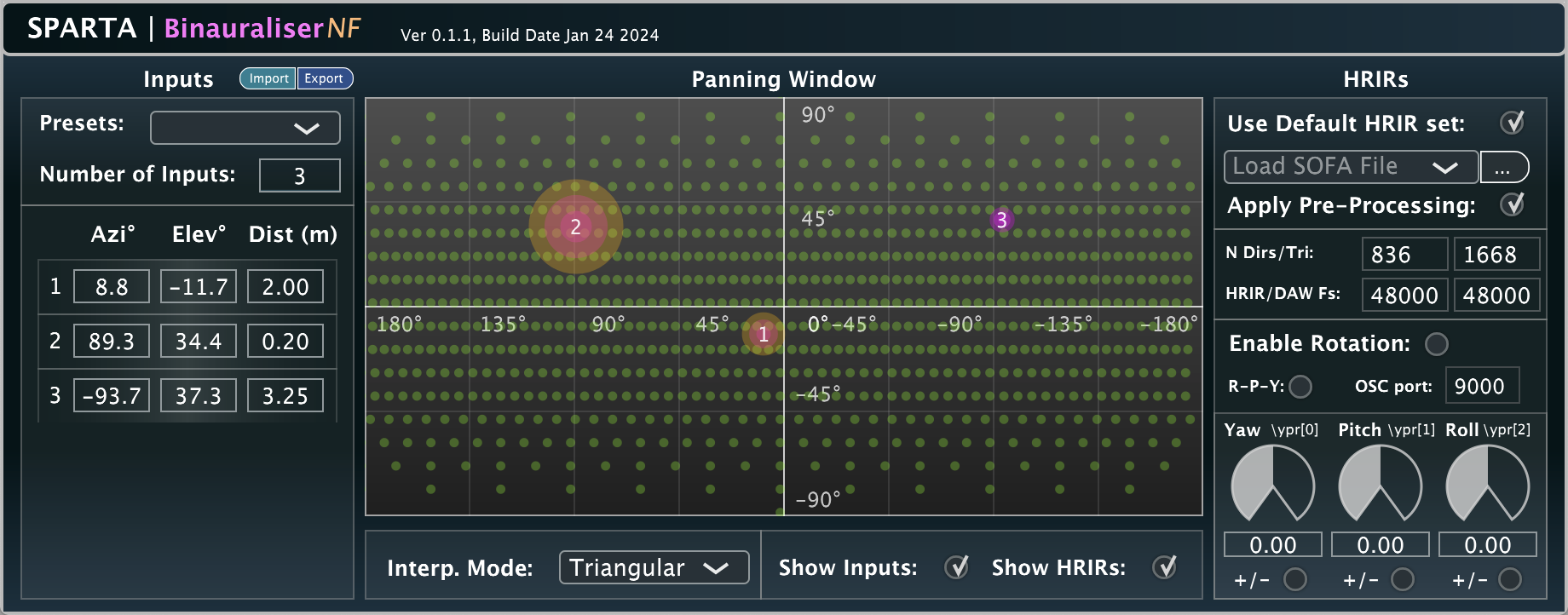
Input: Object audio signals | Output: Binaural
This plug-in mirrors the functionality of the Binauraliser, with the addition of proximity filtering, which reproduces the binaural effects of nearby sound sources. The implementation follows a shelving filter scheme described in [15].
Developers: Michael McCrea, Leo McCormack, and Sebastian Schlecht.
Decorrelator
Input: Any multichannel signal | Output: Any multichannel signal
A simple multi-channel signal decorrelator (up to 128 channels) based on randomised time-frequency delays and cascaded all-pass filters.
Developers: Leo McCormack
DirASS
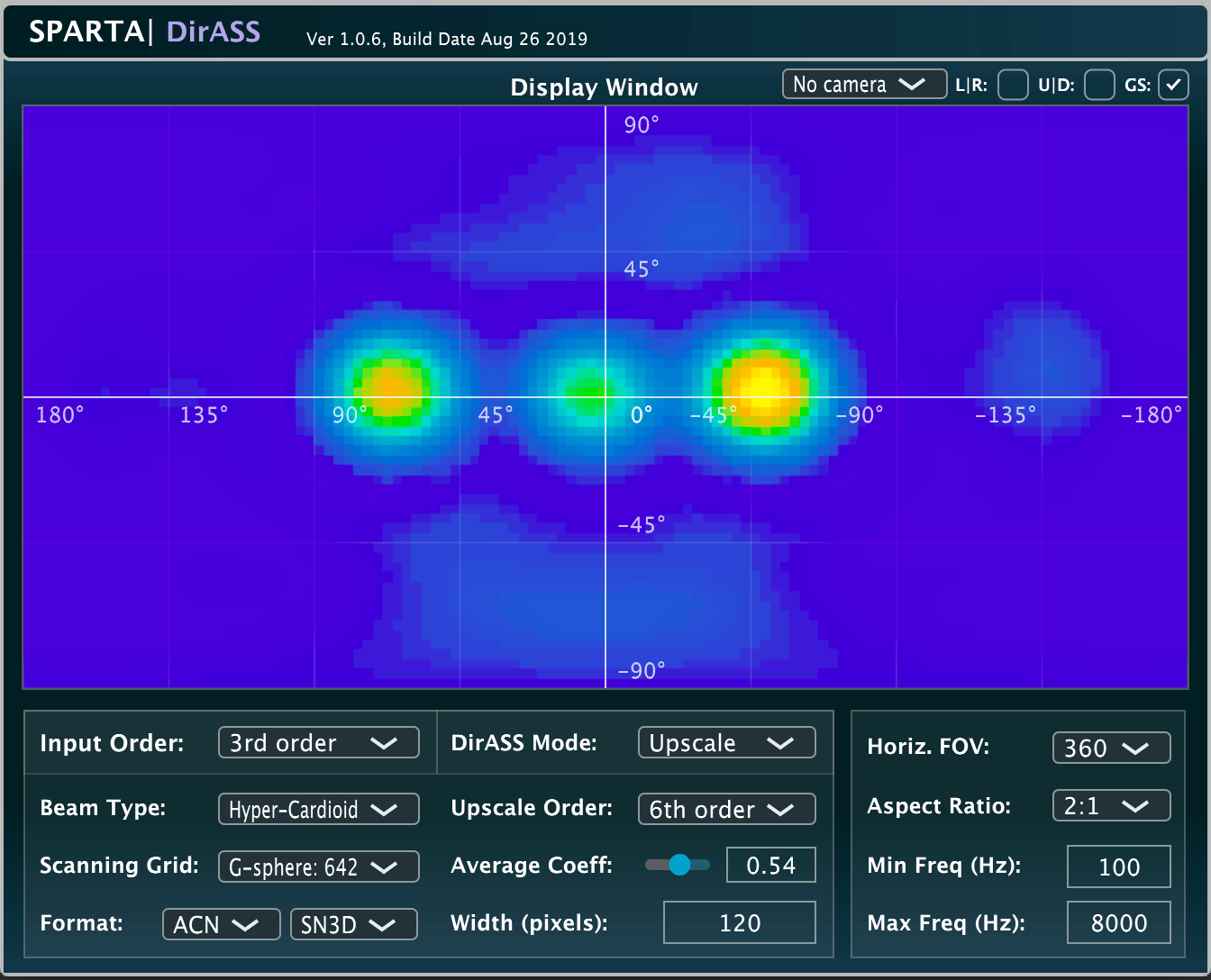
Input: Ambisonics | Output: N/A | Related publication
A sound-field visualiser, which is based on the directional re-assignment of beamformer energy. This energy re-assignment is based on local DoA estimates for each scanning direction, and may either be quantised to the nearest direction or upscaled to a higher-order than the input (resulting in sharper activity-maps). For example, a second-order input may be displayed with (up to) 20th order output resolution. The plug-in also allows the user to place real-time video footage behind the activity-map, in order to create a make-shift acoustic camera.
In essence, DirASS may be viewed as the visualiser counterpart to DirAC.
Developers: Leo McCormack and Archontis Politis.
MatrixConv
Input: Any multichannel signal | Output: Any multichannel signal
A flexible matrix convolver. The matrix of filters should be concatenated for each output channel and loaded as a .wav file. You need only inform the plug-in of the number of input channels, and it will take care of the rest.
- Example 1, spatial reverberation: if you have a B-Format/Ambisonic room impulse response (RIR), you may convolve it with a monophonic input signal and the output will exhibit (much of) the spatial characteristics of the measured room. Simply load this Ambisonic RIR into the plug-in and set the number of input channels to 1.
- Example 2, microphone array to Ambisonics encoding: if you have a matrix of filters to go from an Eigenmike (32 channel) recording to 4th order Ambisonics (25 channel), then the plug-in requires a 25-channel wav file to be loaded, and the number of input channels to be set to 32. In this case: the first 32 filters will map the input to the first output channel, filters 33-64 will map the input to the second output channel, … , and the last 32 filters will map the input to the 25th output channel. An example of such an encoding matrix may be downloaded from here. Note that these example filters employ the ACN/N3D convention, Tikhonov regularisation, and 15dB of maximum gain amplification; using the Matlab scripts from here.
- Example 3, more advanced spatial reverberation: if you have a monophonic recording of a trumpet and you wish to reproduce it as if it were in your favourite concert hall, first measure a B-Format/Ambisonic room impulse response (RIR) of the hall, and then convert this Ambisonic RIR to your loudspeaker set-up using e.g. HO-SIRR. Then load the resulting rendered loudspeaker array RIR into the plug-in and set the number of input channels to 1. An example of a 12point T-design loudspeaker array IR, made using a simulation [12] of the Vienna Musikverein concert hall, may be downloaded from here.
- Example 4, virtual monitoring of a multichannel setup: if you have a set of binaural head-related impulse responses (BRIRs) which correspond to the loudspeaker directions of a measured listening room, you may use this 2 x numLoudspeakers matrix of filters to reproduce loudspeaker mixes over headphones. Simply concatenate the BRIRs for each input channel into a two channel wav file and load them into the plug-in, then set the number of inputs to be the number of loudspeakers used for the mix.
Developers: Leo McCormack and Archontis Politis.
MultiConv
Input: Any multichannel signal | Output: Any multichannel signal
A multi-channel convolver. The plug-in will convolve each input channel with the respective filter up to the maximum of 128 channels/filters. The filters are loaded as a multi-channel .wav file.
Please note that this is not to be confused with the MatrixConv plug-in. For this plug-in, the number inputs = the number of filters = the number of outputs. i.e. no matrixing is applied.
- Example, headphone equalisation: you may minimise the effect that your headphones have on the binaural output, by also convolving with (regularised) inverse headphone transfer function filters. These filters may either be based on measurements of your own head and headphones, or you may download generic ones. For example, you can find equalisation filters for many commercially available headphones from here [13].
Developers: Leo McCormack and Archontis Politis.
6DoFconv
Input: Any multichannel signal | Output: Any multichannel signal | Related publication
A time-varying partitioned convolution multi-channel convolver for SOFA files containing RIRs with multiple listener positions.
- Example, spatial reverberation: if you have a SOFA file of a dataset of B-format/Ambisonic spatial room impulse responses (SRIRs) with varying listener position, you may convolve one with a monophonic input signal, whereby the listener position (X, Y and Z coordinates) determines the SRIR selection. You may then decode the resulting Ambisonic output to your loudspeaker array (e.g. using SPARTA|AmbiDEC) or to headphones (e.g. using SPARTA|AmbiBIN). An example of SOFA files in a compatible format is the coupled room transition dataset (https://doi.org/10.5281/zenodo.4095493). For this, you may choose to use OSC signals in the format \xyzypr (denoting positional coordinates x, y, z and rotation yaw, pitch and roll) to control the listener position and orientation (if you enable the built-in rotator).
Developers: Rapolas Daugintis, Thomas McKenzie, Nils Meyer-Kahlen and Leo McCormack.
Panner
Input: Object audio signals | Output: Arbitrary loudspeaker array
A frequency-dependent 3D panner based on the Vector-base Amplitude Panning (VBAP) method [4]. Presets for popular 2D and 3D formats are included for convenience; however, the directions for up to 128 channels can be independently controlled for both inputs and outputs. The panning is frequency-dependent to accommodate the method described in [5], which allows for more consistent loudness when sources are panned in-between the loudspeaker directions.
Set the “Room Coeff” parameter to 0 for standard power-normalisation, 0.5 for a listening room, and 1 for an anechoic chamber.
Developers: Leo McCormack, Archontis Politis and Ville Pulkki.
PitchShifter
Input: Any multichannel signal | Output: Any multichannel signal
A simple multi-channel pitch shifter (up to 128 channels) based on the phase vocoder approach.
Developers: Leo McCormack
PowerMap
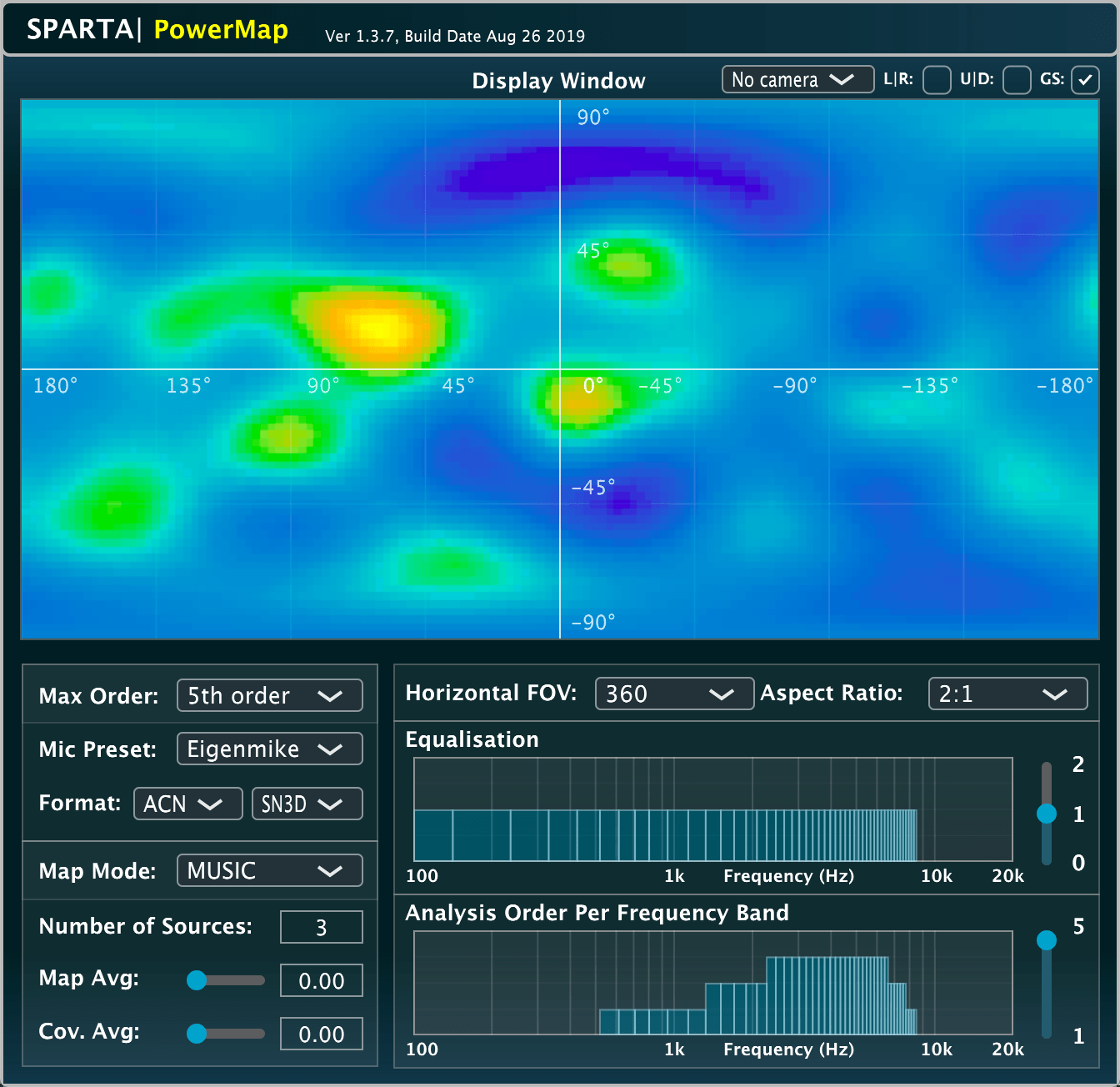
Input: Ambisonics | Output: N/A | Related publication
A plug-in that represents the relative energy (or the statistical likelihood) of sounds arriving at the receiver position from different directions. Yellow indicates high sound energy/likelihood and blue indicates low sound energy/likelihood. The plug-in integrates a variety of different approaches, including: standard Plane-Wave Decomposition (PWD), Minimum-Variance Distortionless Response (MVDR), Multiple Signal Classification (MUSIC), and the Cross-Pattern Coherence (CroPaC) algorithm [3]. Note that the analysis order per frequency band is entirely user definable, and presets for higher order microphone arrays have been included for convenience, which provide some rough starting values. The plug-in also allows the user to place real-time video footage behind the activity-map, in order to create a make-shift acoustic camera.
Developers: Leo McCormack and Symeon Delikaris-Manias.
Rotator

Input: Ambisonics | Output: Ambisonics
Rotates the Ambisonic sound scene [6]. The rotation angles can be controlled using a head tracker via OSC messages. Simply configure the headtracker to send a vector: ‘\ypr[3]’ to OSC port 9000 (default); where \ypr[0], \ypr[1], \ypr[2] are the yaw-pitch-roll angles, in degrees, respectively. The angles can also be flipped +/- in order to support a wider range of devices. The rotation order (yaw-pitch-roll (default) or roll-pitch-yaw) can also be specified. Alternatively, the rotation can be based on a Quaternion by sending vector: ‘\quaternion[4]'; where \quaternion[0], \quaternion[1], \quaternion[2], \quaternion[3], are the W, X, Y, Z parts of the Quaternion, respectively.
Developers: Leo McCormack
SLDoA
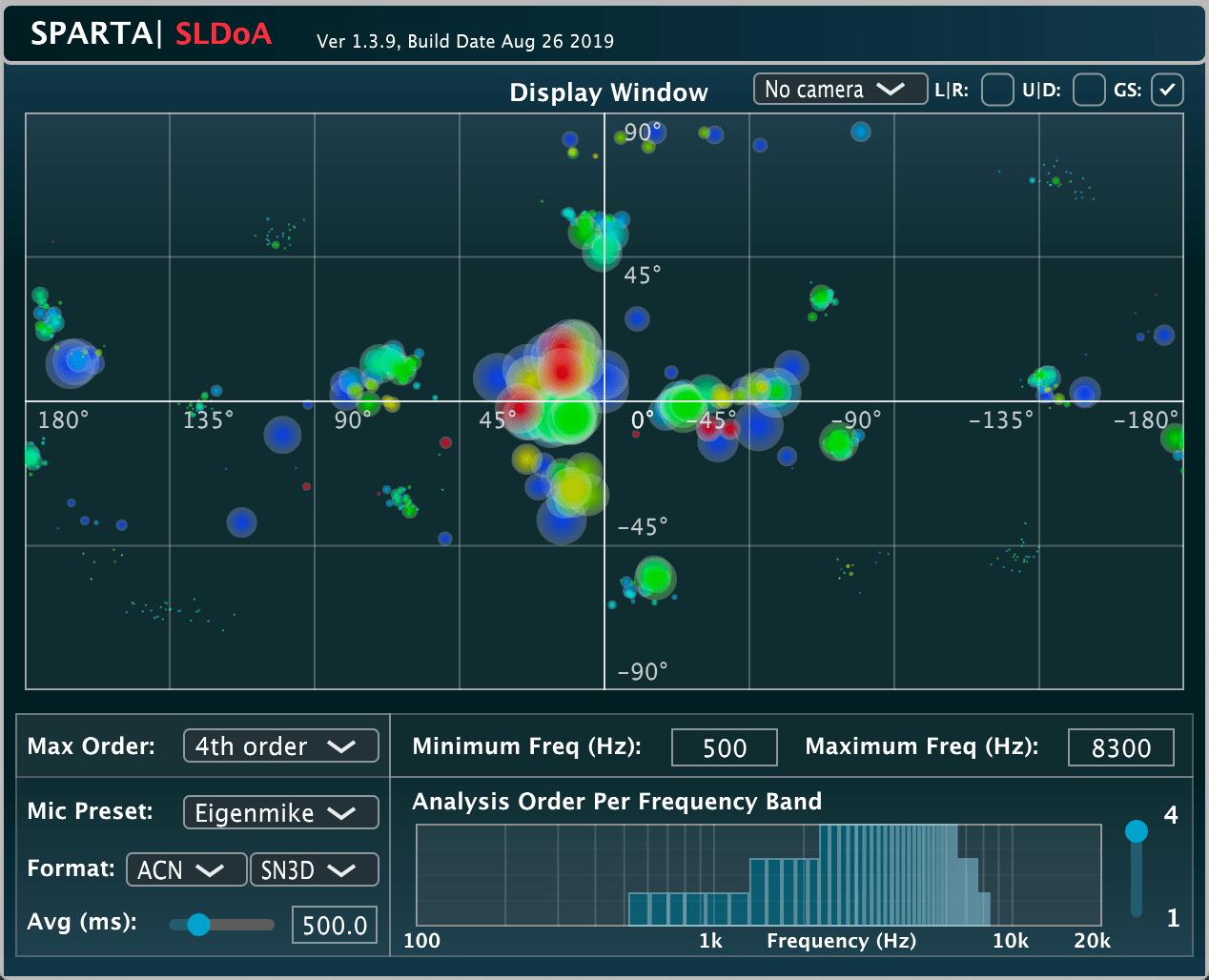
Input: Ambisonics | Output: N/A | Related publication
A spatially localised direction-of-arrival (DoA) estimator. The plug-in performs DoA estimation in several spatially-constrained sectors on the sphere for each frequency-band independently. The low frequency estimates are depicted with blue icons, mid-frequencies with green, and high-frequencies with red. The size of the icon and its opacity correspond to the energy of the sector, which are normalised and scaled in ascending order for each frequency band. The analysis order per frequency band is user definable, as is the frequency range at which to analyse. The plug-in also allows the user to place real-time video footage behind the activity-map, in order to create a make-shift acoustic camera.
Developers: Leo McCormack and Symeon Delikaris-Manias.
Spreader
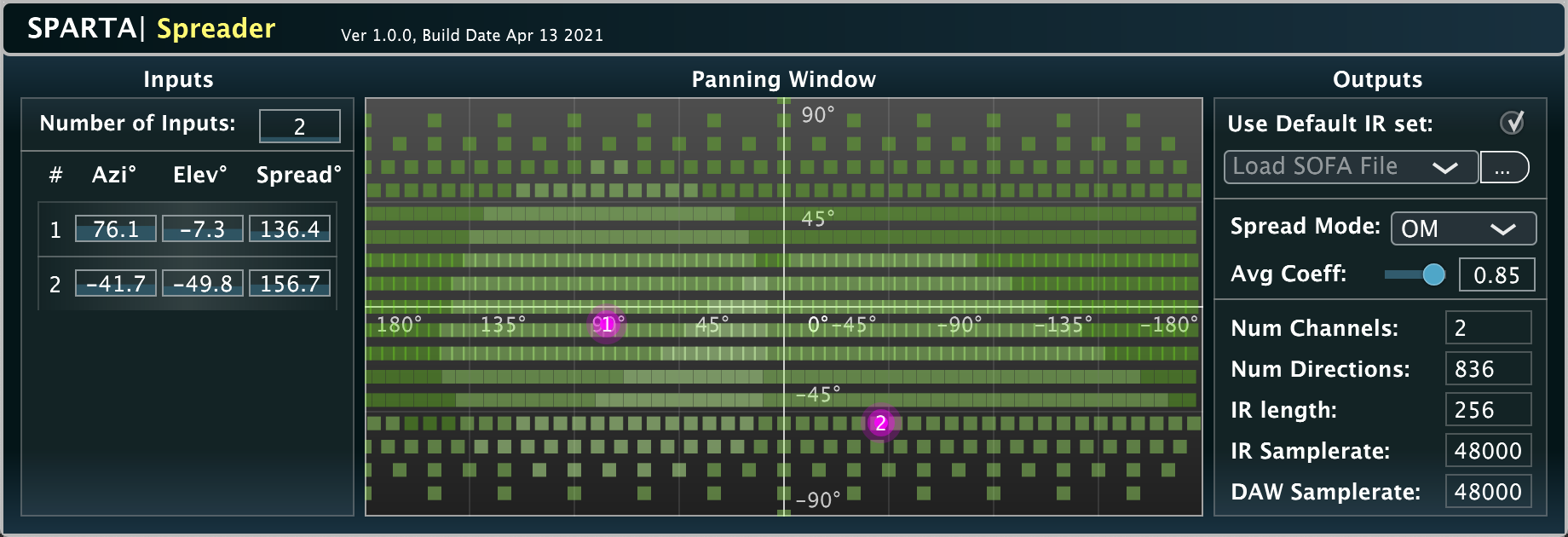
Input: Object audio signal | Output: Any multichannel signal | Related publication
An object spatial spreader for arbitrary playback systems.
Developers: Leo McCormack and Archontis Politis.
About the developers
- Leo McCormack: former postdoctoral researcher at Aalto University.
- Symeon Delikaris-Manias: former postdoctoral researcher at Aalto University.
- Archontis Politis: professor at Tampere University.
- Ville Pulkki: professor at Aalto University.
- Christoph Hold: doctor of science from Aalto University.
- Michael McCrea: audio R&D engineer.
- Sebastian Schlecht: professor at Friedrich-Alexander-Universität Erlangen-Nürnberg.
- Rapolas Daugintis: PhD from Imperial College London.
- Thomas McKenzie: lecturer in acoustics at the University of Edinburgh.
- Nils Meyer-Kahlen: postdoctoral researcher at Aalto University.
- Janani Fernandez: postdoctoral researcher at Tampere University.
License
All of the plug-ins in the SPARTA suite may be used for academic, personal, and/or commercial use. The source code may also be used for commercial purposes, provided that the terms of the GPLv3 license are honoured. This requires that the original code and/or any derived works must also be open-sourced and made available under the same GPLv3 license, if it is to be used for commercial purposes.
References
[1] Zotter, F., Frank, M. (2012). All-Round Ambisonic Panning and Decoding.
Journal of the Audio Engineering Society, 60(10), 807-820.
[2] Zotter, F., Pomberger, H., Noisternig, M. (2012). Energy-Preserving Ambisonic Decoding.
Acta Acustica United with Acustica, 98(1), 37-47.
[3] Delikaris-Manias, S., Pulkki, V. (2013). Cross pattern coherence algorithm for spatial filtering applications utilizing microphone arrays.
IEEE Transactions on Audio, Speech, and Language Processing, 21(11), 2356-2367.
[4] Pulkki, V. (1997). Virtual Sound Source Positioning Using Vector Base Amplitude Panning.
Journal of the Audio Engineering Society, 45(6), 456-466.
[5] Laitinen, M., Vilkamo, J., Jussila, K., Politis, A., Pulkki, V. (2014). Gain normalization in amplitude panning as a function of frequency and room reverberance.
55th International Conference of the AES. Helsinki, Finland.
[6] Ivanic, J., Ruedenberg, K. (1998). Rotation Matrices for Real Spherical Harmonics. Direct Determination by Recursion Page: Additions and Corrections.
Journal of Physical Chemistry A, 102(45), 9099-9100.
[7] Moreau, S., Daniel, J., Bertet, S. (2006). 3D sound field recording with higher order ambisonics-objective measurements and validation of spherical microphone.
in Audio Engineering Society Convention 120, Audio Engineering Society
[8] Politis, A., Gamper, H. (2017). Comparing Modelled And Measurement-Based Spherical Harmonic Encoding Filters For Spherical Microphone Arrays.
In IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA).
[9] Delikaris-Manias, S., McCormack, L., Huhtakallio, I., and Pulkki, V. (2018) Real-time underwater spatial audio: a feasibility study.
in Audio Engineering Society Convention 144, Audio Engineering Society.
[10] Zaunschirm, M., Schörkhuber, C., and Höldrich, R. (2018). Binaural rendering of Ambisonic signals by head-related impulse response time alignment and a diffuseness constraint.
The Journal of the Acoustical Society of America, 143(6), 3616-3627.
[11] Schörkhuber, C., Zaunschirm, M., and Höldrich, R. (2018). Binaural Rendering of Ambisonic Signals via Magnitude Least Squares.
In Proceedings of the DAGA (Vol. 44).
[12] Favrot, S. and Buchholz, J.M., (2019). LoRA: A loudspeaker-based room auralization system.
Acta Acustica united with Acustica, 96(2), pp.364-375.
[13] Bernschutz, B., (2013). A spherical far field HRIR/HRTF compilation of the Neumann KU 100.
In Proceedings of the 40th Italian (AIA) annual conference on acoustics and the 39th German annual conference on acoustics (DAGA) conference on acoustics (p. 29). AIA/DAGA.
[14] McCormack, L. Politis, A., and Pulkki, V., 2021, October. Rendering of source spread for arbitrary playback setups based on spatial covariance matching. In 2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE.
[15] Spagnol, S., Tavazzi, E., and Avanzini, F. “Distance rendering and perception of nearby virtual sound sources with a near-field filter model.”
Applied Acoustics, vol. 115, pp. 61–73, Jan. 2017.
Other included plug-ins
The SPARTA installer also includes:
- The COMPASS suite COMPASS →
- The HO-DirAC suite HO-DirAC →
- The HO-SIRR application HO-SIRR →
- The CroPaC-Binaural decoder CroPaC-Binaural →