HO-DirAC
HO-DirAC is a collection of parametric spatial audio plug-ins.
These plug-ins conform to the Ambisonic Channel Number (ACN) ordering convention and offer support for both orthonormalised (N3D) and semi-normalised (SN3D) normalisation schemes (note that the AmbiX format refers to the combination of ACN and SN3D). The maximum transform order for these plug-ins is 3rd.
Plug-in descriptions
Example REAPER projects can be found here.
Decoder
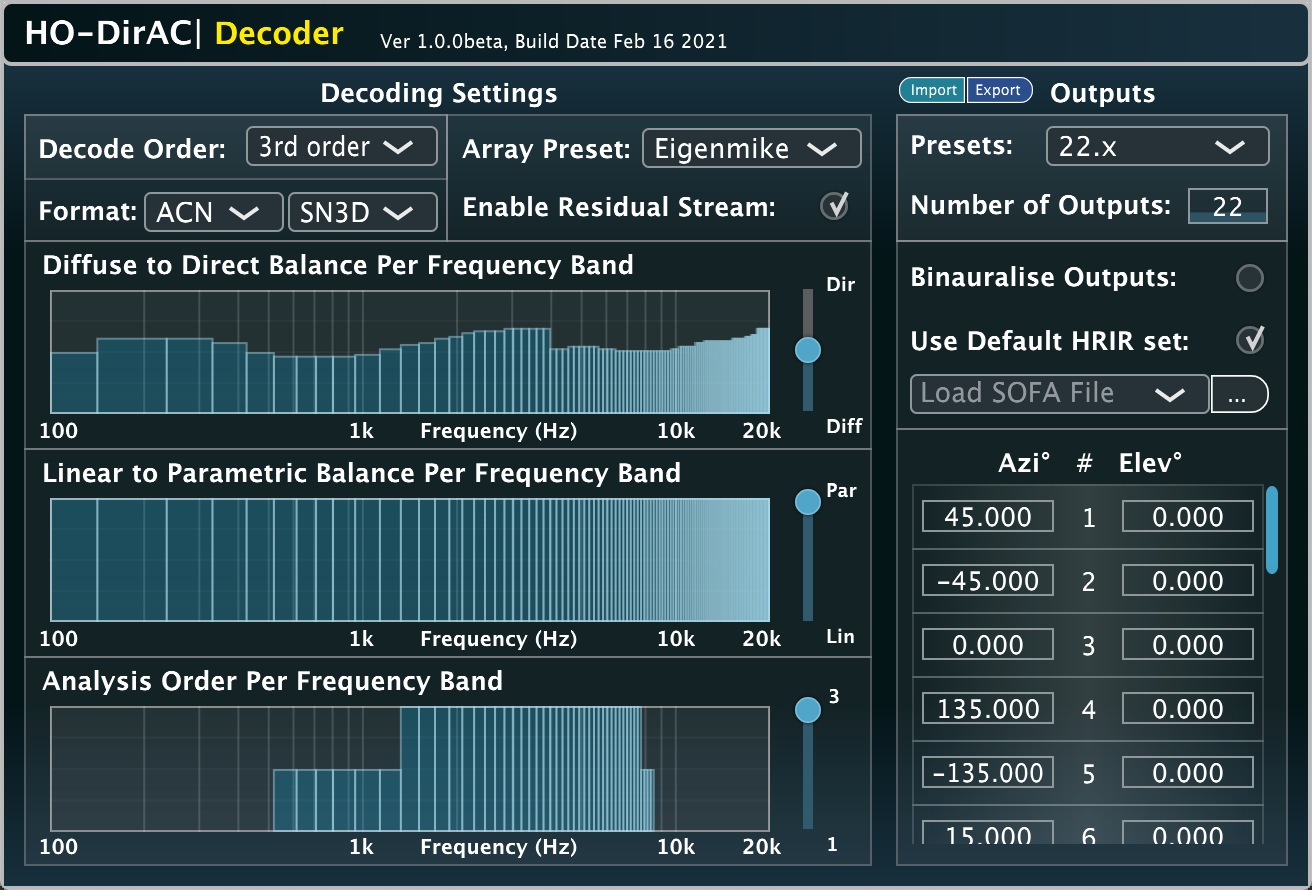
Input: Ambisonics | Output: Arbitrary loudspeaker array | Related publication
An Ambisonic loudspeaker decoder based on the Higher-order Directional Audio Coding (HO-DirAC) method.
The “Diffuse-to-Direct” control allows the user to give more prominence to the direct sound components (an effect similar to de-reverberation), or to the ambient component (an effect similar to emphasising reverberation in the recording). The “Linear-to-Parametric” control lets you control the balance between HO-DirAC decoding and EPAD decoding. When using Ambisonic signals derived from microphone arrays, the frequency ranges at which higher-order components can be obtained varies depending on the order; in these cases, the “Analysis-order” may be specified per frequency band to account for these inperfect input Ambisonic signals.
The plug-in is considered by the authors a production tool and, due to its time-frequency processing, requires internal audio buffer sizes of at least 2048 samples. Hence we do not consider it as a low-latency plug-in and therefore it is not suitable for interactive input. For cases such as interactive binaural rendering for VR with head-tracking, please use the HO-DirAC|Binaural version.
Binaural
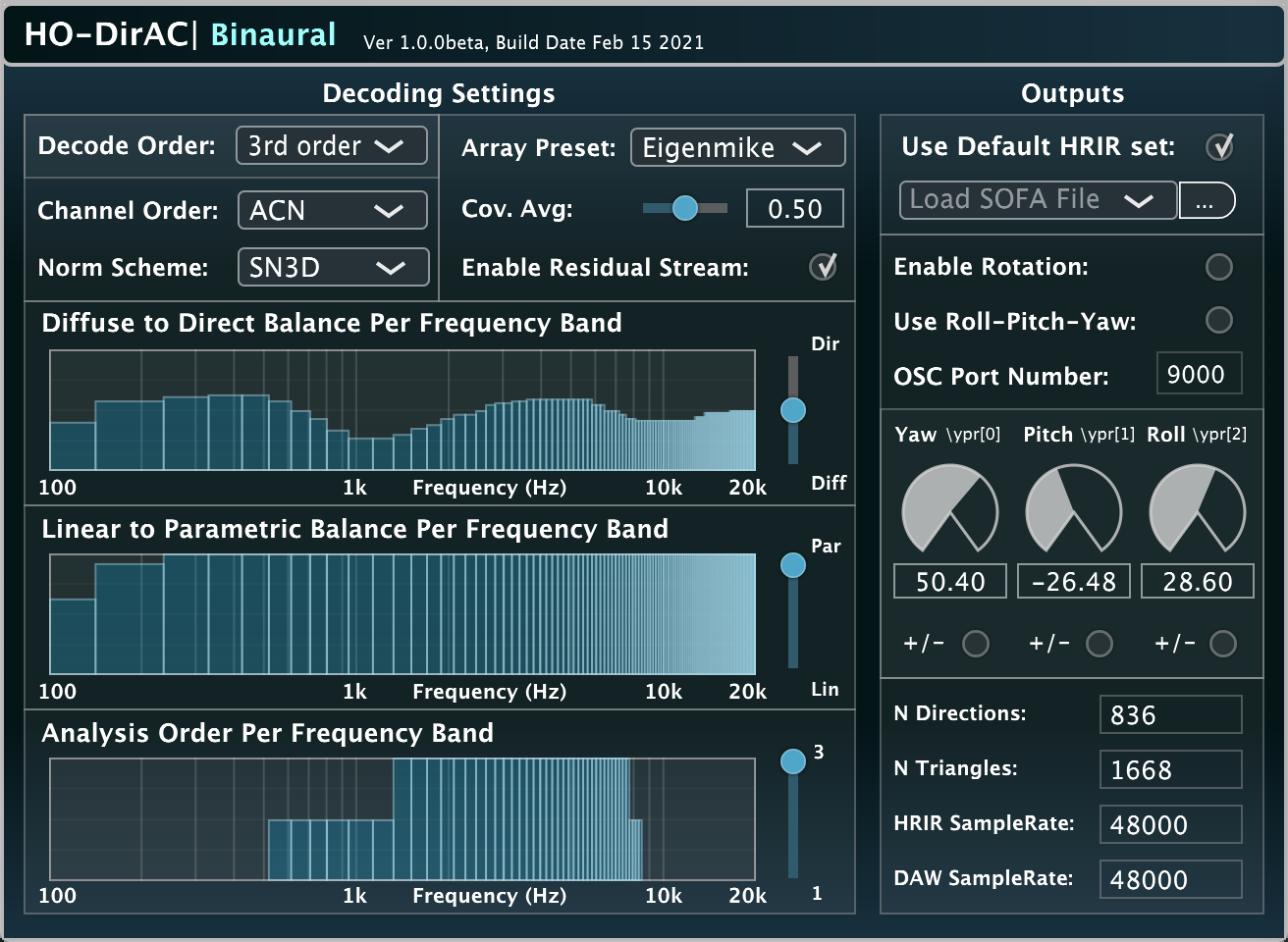
Input: Ambisonics | Output: Binaural | Related publication
This is an optimised version of the HO-DirAC decoder for binaural playback, which bypasses loudspeaker rendering by using binaural filters (HRTFs) directly, which can be user-provided and personalised with the SOFA format. For the plug-in parameters, see the description of the HO-DirAC|Decoder above. Additionally the plug-in can receive OSC rotation angles from a headtracker at a user specified port, in the yaw-pitch-roll convention.
This version is intended mostly for head-tracked binaural playback of Ambisonic content at interactive update rates, usually in conjunction with a head-mounted display (HMD). The plug-in requires an audio buffer size of at least 512 samples (~10msec at 48kHz).
Upmixer
Input: Ambisonics | Output: (higher-order) Ambisonics
This plug-in is intended for the task of upmixing a lower-order Ambisonic recording to a higher-order Ambisonic recording. It is essentially a wrapper for HO-DirAC|Decoder, as it first decodes the input to an appropriate uniform arrangement of virtual loudspeakers (e.g. a t-design) followed by re-encoding the virtual loudspeaker signals into the target order. It can be used by users who are already working with a preferred linear Ambisonic decoding workflow of higher-order Ambisonic content, and wish to combine lower-order Ambisonic material with increased spatial resolution. One can upmix first, second, or third-order material (4,9,16 channels) up to fifth-order material (36 channels).
The HO-DirAC framework
Directional Audio Coding (DirAC) has been an active research topic at Aalto University since 2007 [1]. The method operates by estimating spatial parameters to describe the input sound scene over time and frequency, which are then used to conduct the mapping of the input Ambisonic signals to the output loudspeaker/binaural channels in an adaptive and informed manner. While the original intention of DirAC was for low bitrate compression and transmission of Ambisonic recordings, more recent years have instead focussed on using it for the enhancement of Ambisonics reproduction.
These particular audio plug-in implementations use the higher-order analysis designs described in [2,3], which synthesise the target output signals based on the optimal covariance domain rendering framework described in [4].
About the developers
These plug-ins were developed by Leo McCormack. However, a number of people were involved in the research of the underlying algorithms, and much of the internal C/C++ code is based on Matlab code written by Archontis Politis and Juha Vilkamo; who, in turn, based their code and research on the code and research of: Mikko-Ville Laitinen, Jukka Ahonen, Tapani Pihlajamäki, and Ville Pulkki. For a detailed history of the method the reader is referred to [5].
License
These audio plug-ins, which incorporate Aalto University’s implementation of the DirAC technology, are provided for academic, personal and/or non-commercial use by a non-enterprise end-user. Any exploitation of the plug-ins for other purposes may require a license from Fraunhofer IIS. For commercial implementations of DirAC technology, the user is instead referred to upHear.
References
[1] Pulkki, V. (2007) Spatial sound reproduction with directional audio coding.
Journal of the Audio Engineering Society 55.6: 503-516.
[2] Politis, A., Vilkamo, J., and Pulkki, V. (2015). Sector-based parametric sound field reproduction in the spherical harmonic domain.
IEEE Journal of Selected Topics in Signal Processing, 9(5), 852-866.
[3] Politis, A., McCormack, L., and Pulkki, V. (2017, October). Enhancement of ambisonic binaural reproduction using directional audio coding with optimal adaptive mixing.
In 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) (pp. 379-383). IEEE.
[4] Vilkamo, J., Bäckström, T., and Kuntz, A. (2013). Optimized covariance domain framework for time-frequency processing of spatial audio.
Journal of the Audio Engineering Society, 61(6), 403-411.
[5] Pulkki, V., Delikaris-Manias, S., and Politis, A. (Eds.). (2018). Parametric time-frequency domain spatial audio.
John Wiley and Sons, Incorporated.